


目录
近日,字节跳动豆包大模型团队宣布开源Multi-SWE-bench,这是业内首个多语言代码修复基准数据集,为大模型“自动修Bug”能力的评估与提升带来新突破。
在大模型技术快速发展的当下,代码生成任务成为检验模型智能的关键领域。以SWE-bench为代表的代码修复基准,虽能衡量模型的编程智能,但存在明显局限。其仅聚焦Python语言,无法评估模型跨语言泛化能力;且任务难度有限,难以覆盖复杂开发场景,制约了大模型代码智能的进一步发展。
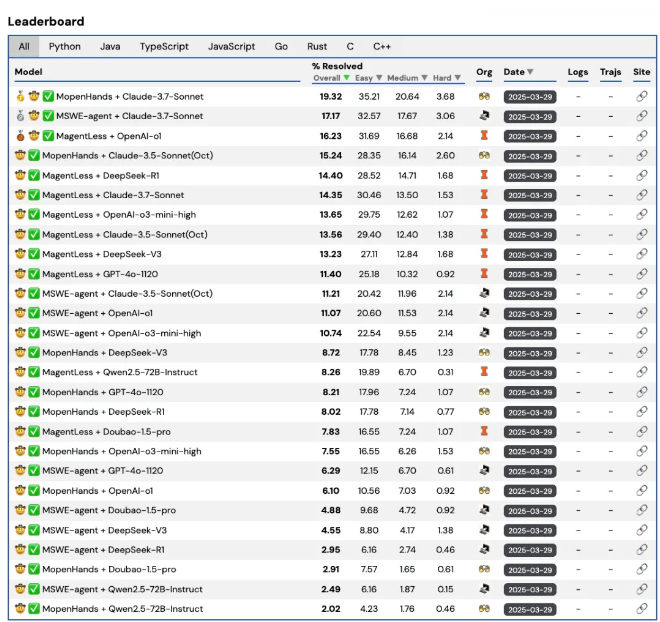
Multi-SWE-bench应运而生,它在SWE-bench基础上实现重大跨越,首次覆盖Java、TypeScript、C、C++、Go、Rust和JavaScript等7种主流编程语言,构建了1632个源于真实开源仓库的修复任务。这些任务经过严格筛选与人工验证,确保质量可靠。同时,Multi-SWE-bench引入难度分级机制,分为简单、中等、困难三类,能更全面评估模型在不同能力层次的表现。
基于该数据集的实验显示,当前大语言模型在Python修复上表现尚可,但处理其他语言时平均修复率不足10%,凸显多语言代码修复仍是大模型面临的挑战。
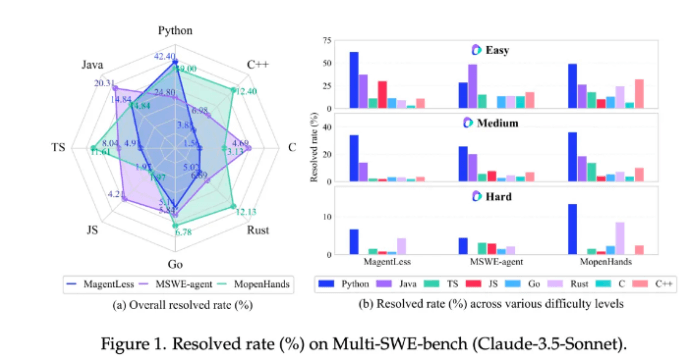
部分主流模型在 Python 上表现更为优异,面向其他语言则分数不佳。同时,随着任务难度增加,模型修复率呈现逐级下降趋势。
为配合强化学习在自动编程领域的应用,团队还同步开源了Multi-SWE-RL,提供4723个实例及配套的可复现Docker环境,支持一键启动、自动评估等功能,为RL训练打造了标准化数据基础。此外,团队启动开源社区计划,诚邀开发者和研究者参与数据集扩展、新方法评测等工作,共同推进RL for Code生态建设。
字节跳动豆包大模型团队表示,希望Multi-SWE-bench能推动自动编程技术迈向新高度,未来将持续拓展其覆盖范围,助力大模型在“自动化软件工程”领域取得更大进展。

